Introduction
Le marketing mix modeling (MMM) est un ensemble de méthodes statistiques qui permet d’évaluer l’impact des différentes actions marketing sur les ventes et les revenus d’une entreprise. Cette approche d’aide à la décision permet, par conséquent, d’optimiser la répartition du budget marketing entre les différents canaux et actions promotionnelles.
Le MMM repose sur l’analyse de séries temporelles de données de ventes et des coûts marketing. Que cela soit à l’aide de régressions simples ou de techniques de machines learning avancées, le MMM permet in fine de modéliser le retour sur investissement (ROI) de chaque action marketing et de rendre prévisible l’impact de futurs scénarios.
Cet article a pour but d’introduire deux méthodologies connues utilisées pour réaliser ce type d’analyse, pourquoi elles sont utiles et comment elles diffèrent.
Les manières de faire
Pour une entreprise souhaitant réaliser un MMM, il existe en réalité une multitude de manières de procéder. Par exemple, il est possible de
- Faire appel à des sociétés spécialisées qui ont des modèles propriétaires(souvent SaaS)
- Lancer votre propre méthodologie
- Utiliser du code open-source existant et l’adapter à votre business
Les modèles propriétaires ont souvent l’avantage d’être plus simples à utiliser. Néanmoins, leur méthodologie reste obscure dans le sens où les propriétaires peuvent être réticents à dévoiler les mécanismes de leurs modèles afin de conserver l’exclusivité de leur savoir-faire. De plus, dans le cadre du SaaS, les spécificités de votre entreprise seront difficiles à intégrer, à moins que la société propriétaire procède à des modifications sur mesure, limitant ainsi les avantages d’une solution Saas.
Pour ce qui est de coder son modèle soi-même, cela représente un énorme challenge. Il faut avoir des connaissances très pointues en machine learning et en économétrie. Il faut également consacrer beaucoup de temps pour faire des tests, coder le programme, etc. Nous ne recommandons pas cette méthode à moins que les modèles SaaS et open-source ne puissent être appliqués à votre société.
Finalement, il y a les modèles open-source, dont les plus populaires sont Robyn et LightweightMMM. L’un est développé par Meta, l’autre par Google. Chacun possède sa propre méthodologie. Bien que leur code source soit disponible en ligne, aucune assistance n’est fournie pour la mise en place, ce qui nécessite une expertise avancée en programmation et en science des données pour le calibrage du modèle.
Robyn vs LightweightMMM
Bien que Robyn et LightweightMMM aient des différences techniques, leur objectif fondamental reste le même : alimenter le modèle avec les coûts marketing et les ventes afin d’identifier les effets de chaque canal marketing sur les ventes.
Parmi les similarités des modèles, les deux permettent la prise en compte de deux phénomènes très importants dans le domaine publicitaire:
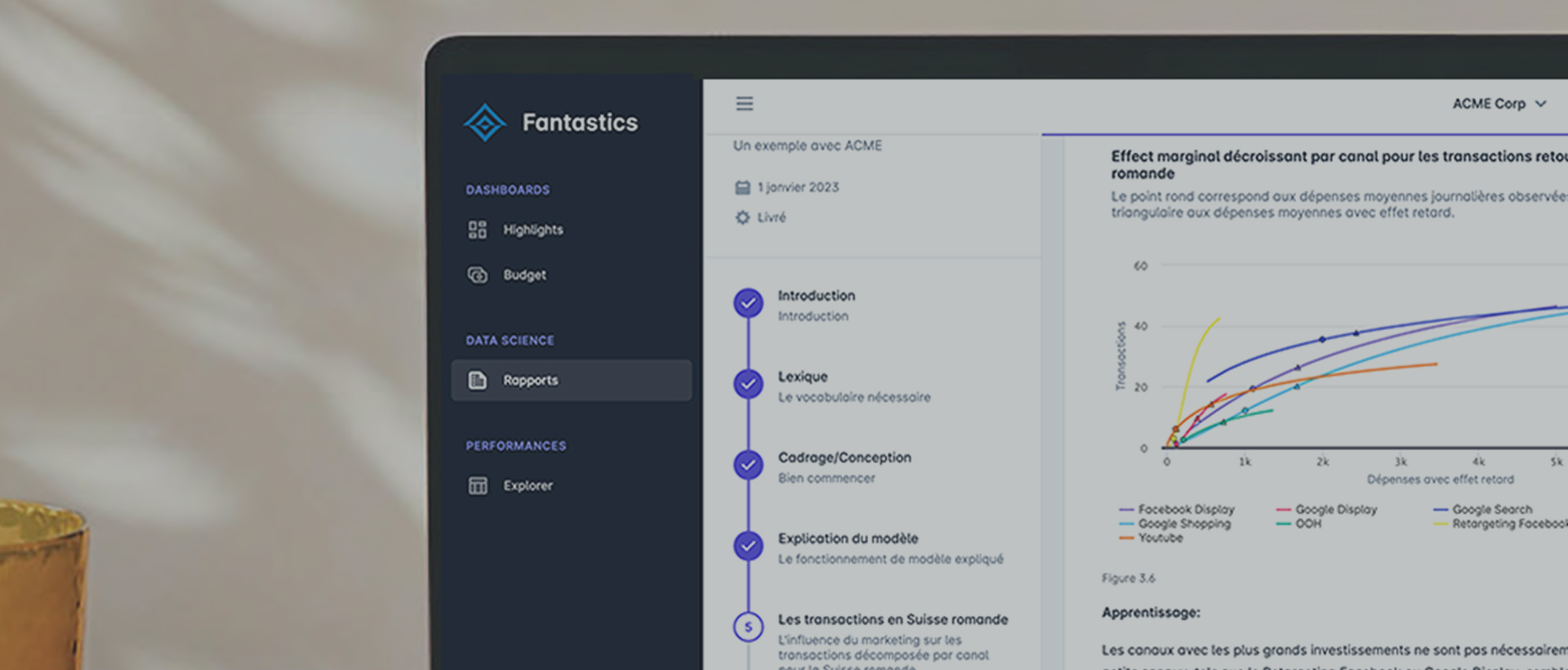
- L’effet marginal décroissant: Peut être expliqué de manière simple en utilisant l’exemple de la publicité. Le propriétaire d’une entreprise décide d’investir dans la publicité pour augmenter ses ventes. Au début, chaque CHF investi dans la publicité augmente considérablement les ventes. Cependant, à mesure qu’il continue d’investir sur un même levier média, l’augmentation des ventes pour chaque CHF supplémentaire investi devient de moins en moins importante. C’est ce qu’on appelle l’effet marginal décroissant.
- L’effet retard (adstock): L’effet retard est un concept utilisé pour tenir compte des effets de report de la publicité. L’adstock fait référence à la quantité d’impact qu’a une publicité sur le comportement des consommateurs après l’arrêt de la publicité. Pour expliquer cela de manière simple, prenons l’exemple d’une entreprise qui lance une campagne publicitaire pour un nouveau produit. Même après la fin de la campagne publicitaire, les consommateurs peuvent continuer à se souvenir du produit et à l’acheter grâce à l’effet résiduel de la publicité. C’est ce qu’on appelle l’effet retard.
Cependant, la différence entre les modèles réside dans la façon de mesurer ces phénomènes. Robyn utilise une méthodologie fréquentiste tandis que le LightweightMMM utilise des techniques bayésiennes. Sans rentrer dans les détails techniques, les méthodes fréquentistes estiment les paramètres recherchés en observant les données passées uniquement. Les modèles bayésiens requièrent un savoir préalable des effets. Par exemple, pour estimer le ROI d’un canal, par exemple Google Search, le modèle bayésien nous demandera une fourchette de valeur à lui fournir, ce qui le guidera dans son analyse. Le modèle fréquentiste ne demandera rien et calculera cette valeur basée sur le passé.
Quel est le meilleur ?
Comme toujours pour ce genre de problème, la réponse est “ça dépend”. Néanmoins voici quelques éléments de réponses pour les comparer:
- Robyn est un package officiellement soutenu par Meta, tandis que LightweightMMM est un package développé par des employés de Google mais qui ne bénéficie pas du soutien officiel de l’entreprise. Cette distinction a un impact sur l’investissement en termes d’efforts fourni à maintenir et développer le package, car les employés de Meta ont pour objectif de l’améliorer continuellement dans le cadre de leur travail. En revanche, pour LightweightMMM, le développement est réalisé sur une base volontaire. Le rendu final s’en fait ressentir dans le sens où Robyn est mieux finalisé et documenté.
- Les méthodes bayésiennes permettent d’introduire du savoir préalable dans le modèle. Cela est relativement utile lorsque certains canaux ont été évalués individuellement dans le passé, en réalisant par exemple un Conversion Lift ou un Geographic Lift, et que nous avons une idée de leur ROI. L’insertion de ce savoir permettra l’obtention d’un modèle cohérent avec le contexte connu. C’est le point fort du LightweightMMM.
Bien que Robyn n’ait pas été initialement conçue pour y insérer du savoir préalable, les créateurs du package ont maintenant prévu des manières de guider le modèle avec des indications qui peuvent lui être données en amont de la modélisation. Cela permet en quelque sorte de répliquer le concept du LightweightMMM. - Étant donné que Robyn s’appuie plus fortement sur les données passées, il nécessite de manière générale plus de données pour être précis.
L’émergence de LightweightMMM, qui est le package le plus récent, nous a récemment poussé à revoir notre manière de faire qui se basait auparavant sur Robyn. Les techniques bayésiennes sont une approche intéressante car elles donnent davantage de contrôle à l’analyste. Si le package LightweightMMM reçoit une attention plus forte de la communauté de marketing analyst et qu’il se développe bien, il se pourrait qu’il devienne plus populaire que Robyn.
A ce jour, notre recommandation finale est de procéder à une pré-étude, qui, selon votre business model, permettra d’opter entre les deux modèles, de repérer les potentielles différences et points communs entre les approches. Cela permettra une validation plus rigoureuse des résultats. Chez bright, nous menons cette pré-étude afin notamment d’adapter notre framework fantastics au projet (traitement des données, exposition des résultats, calculs intermédiaires à réaliser, etc.), de choisir le bon modèle et de définir le périmètre des futures modélisations.