Introduction.
Lorsqu’une entreprise se développe, la complexité de ses processus, des outils qu’elle utilise et de son organisation augmente inévitablement. Passé un certain cap, les analyses basées sur des exports manuels deviennent fastidieuses et difficiles à réaliser, pour plusieurs raisons :
-
- Le nombre d’exports nécessaires pour une seule analyse augmente, en raison de l’utilisation croissante d’outils différents.
- Les analyses se compliquent à mesure que les processus eux-mêmes gagnent en complexité.
- Le volume d’analyses à effectuer s’accroît naturellement avec la croissance de l’entreprise.
- Les risques d’erreurs liés à un manque de documentation augmentent de manière empirique.
Pour automatiser ces analyses — ou du moins une large partie d’entre elles — la mise en place d’une architecture Data adaptée aux besoins devient une solution pertinente. De nombreuses approches et solutions existent sur le marché pour y parvenir. Nous allons en présenter une que nous pensons pertinente et que nous avons l’habitude de déployer pour nos clients.
Les avantages d’une architecture Data.
Parmi les grands bénéfices qui découlent de la mise en place d’une architecture Data, il y a:
- Meilleure fiabilité de la donnée: Une source unique de données (par ex. Big Query) sera utilisée pour la grande majorité des dashboards, ce qui renforcera considérablement la cohérence et la fiabilité des informations. Une base précise pour renforcer les capacités d’attributions.
- Professionnalisation de la gestion de la donnée: Le stockage et le traitement des données seront centralisés autour d’un responsable dédié. Cette centralisation favorisera une meilleure cohérence dans les analyses et dans les conclusions qui en découlent.
- Rapidité: L’automatisation des analyses permet un traitement rapide, régulier et mis à jour sans intervention humaine.
- De nouvelles capacités d’analyse: L’intégration de multiples sources de données, consolidées au sein d’une architecture unifiée, permet la construction de nouveaux indicateurs, exploitables en temps réel dans des solutions de reporting ou via API.
Illustration.
Imaginons une entreprise qui fait face à ce type de funnel de conversion:
- Une personne, intéressée par la publicité faite sur Meta, génère un lead sur Facebook.
- Le lead est rappelé par téléphone. Il s’agit à cette étape d’instaurer la confiance et de cerner les besoins du potentiel client.
- Si le client est intéressé, une offre lui est transmise par email, avec un lien DocuSign pour signer l’offre.
- L’offre est signée électroniquement sur DocuSign.
Ce workflow, simple et réaliste, mobilise pourtant quatre outils différents. Pour analyser manuellement le parcours client, il faut donc concilier au minimum quatre exports de données. Bien que cela puisse être réalisé ponctuellement, la tâche devient vite lourde et chronophage si elle doit être répétée régulièrement.
Pourtant, l’équipe marketing a besoin de suivre en continu le nombre d’offres signées, afin d’orienter les investissements publicitaires et d’identifier les campagnes les plus performantes.
De son côté, l’équipe commerciale doit pouvoir mesurer le pourcentage d’emails qui aboutissent à une signature et le nombre d’appels nécessaires pour conclure une offre. L’équipe financière doit contrôler les coûts engagés par les différents outils, etc.
Sans automatisation, ces informations ne sont pas disponibles à temps, laissant les équipes travailler à l’aveugle et entraînant souvent un manque à gagner important.
La solution.
La mise en place d’une architecture Data vise à “industrialiser et standardiser” le processus d’analyse, afin de garantir la fiabilité des données et la justesse des conclusions qui en découlent.
Une architecture Data complète se structure généralement autour de quatre grandes composantes:
- Sources: Il s’agit d’identifier l’ensemble des données que l’on souhaite collecter. Dans notre exemple, cela correspond aux quatre outils mentionnés précédemment.
- Data Warehouse: C’est la solution centrale où toutes les données collectées depuis les différentes sources sont stockées, centralisées et historisées.
- Transformer: À cette étape, les données brutes sont traitées, réconciliées, agrégées et enrichies pour produire des indicateurs (KPIs) pertinents et exploitables.
- Visualiser: Les résultats sont ensuite restitués via un outil de Business Intelligence (comme Looker Studio), permettant aux équipes de suivre leurs indicateurs.
Deux composants supplémentaires jouent un rôle clé dans la fluidité et la fiabilité de cette architecture
- Pipelines: Ce sont les mécanismes permettant de transporter les données des sources vers le data warehouse. Pour les outils standards (comme Meta), il existe des connecteurs préconstruits. En revanche, pour des sources plus spécifiques, il est parfois nécessaire de développer et maintenir ses propres pipelines, ce qui peut être plus complexe et chronophage.
- Orchestrateur: L’orchestrateur est l’outil qui coordonne l’ensemble du processus, notamment en automatisant la mise à jour des données à intervalles réguliers, afin de garantir que les dashboards affichent toujours des informations à jour.
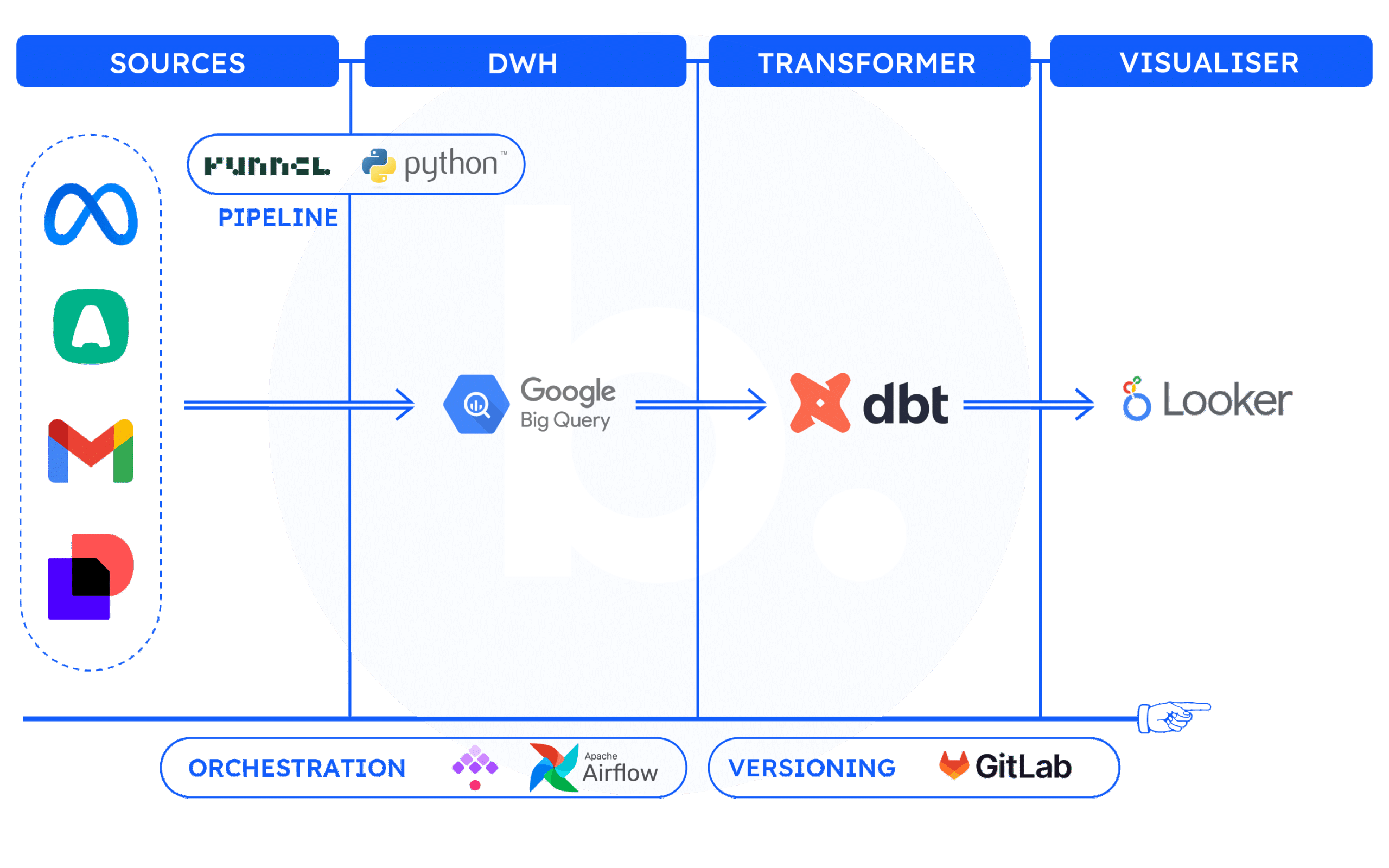
Schéma d’une architecture modulaire de Data Warehouse marketing montrant plusieurs solutions expertes interconnectées via API.
To Be.
Pour reprendre notre exemple précédent, une fois l’architecture data en place, les différentes équipes auront accès aux données actualisées dès leur arrivée au travail, à 8h00.
Chaque équipe disposera de ses propres tableaux de bord et KPIs via la solution de Business Intelligence (Looker Studio), alimentés automatiquement et mis à jour régulièrement. En cas de besoin (ajouts ou modifications), le responsable Data intégrera les évolutions nécessaires dans le workflow existant. Une fois en production, les nouvelles analyses seront disponibles sans perturber le reste du système.
À ce stade, les équipes disposent des informations pertinentes, au bon moment, pour prendre des décisions business éclairées et efficaces.
Parmi les analyses que nous pourrions réaliser dans ce cadre, nous pourrions envisager les choses suivantes:
- Mesurer la quantité et la qualité des leads générés par les actions marketing.
- Visualiser le funnel de conversion afin d’identifier d’éventuels goulets d’étranglement ou des chutes significatives à certaines étapes.
- Analyser le délai de conversion entre le premier clic et la signature du contrat.
- Évaluer le taux de réponse aux campagnes d’e-mailing.
Conclusion.
Une architecture data robuste est essentielle pour toute entreprise souhaitant se développer tout en tirant pleinement parti des outils digitaux. Des données fiables sont indispensables pour prendre des décisions business pertinentes, ce qui implique un processus d’analyse rigoureux et cohérent dans le temps. Les analyses manuelles, bien qu’utiles à court terme, atteignent rapidement leurs limites. Seule une approche automatisée permet de garantir la fiabilité, la pérennité et l’évolutivité des analyses à grande échelle.
En somme, la mise en place d’un Data Warehouse marketing ouvre la voie à une mesure plus fine et objective de la performance. En centralisant les données et en appliquant des modèles d’attribution avancés — jusqu’au Marketing Mix Modeling — les équipes peuvent enfin évaluer le ROI réel de chaque action et piloter leurs investissements sur la base de preuves, non d’intuitions.