Toutes les données utilisateurs vont diminuer en 2023 avec la mise en application de la nLPD / RGPD et la mise en conformité des entreprises sur le respect du consentement lié aux cookies. Cette disparition est vue comme un drame par l’écosystème digital car les annonceurs perdent la capacité d’analyser le ROI des campagnes et donc ne peuvent plus allouer correctement les budgets publicitaires. Sans repères et sans ces précieux outils, nous voici pratiquement de retour à l’âge de pierre.
Toutefois, il existe un certain nombre de solutions pour pallier ce problème, comme le machine learning dont nous allons parler aujourd’hui. En effet, cette disparition des données peut largement être compensée par le déploiement d’algorithmes de machine learning pour combler les trous, comme nous allons pouvoir le constater dans cet article avec le cas de GA4.
Constat : La raréfaction des cookies mène à une déperdition de données depuis plusieurs années et va s’accentuer en 2023
La régulation sur la collecte de données (nLPD) entraîne des conséquences importantes en termes de tracking des campagnes digitales.
La transparence sur la collecte et l’utilisation de données est devenue cruciale pour maintenir la confiance des utilisateurs web, mobile, clients et prospects.
Au-delà du désir pour ces derniers d’obtenir plus de transparence et d’honnêteté, il s’agit surtout du Règlement général européen sur la protection des données (RGPD) entré en application en 2018 qui est la cause principale des bannières de consentement omniprésentes sur internet et des conséquences qui en découlent.
Engendrant une baisse significative du trafic mesuré, cette nouvelle réglementation a impacté les performances et la fiabilité des rapports provenant des canaux d’acquisition et des campagnes, conduisant fatalement à une analyse du retour sur investissement imprécise, voire péjorée.
Les entreprises doivent depuis faire face à un défi de taille : acquérir des données fiables tout en respectant les choix de confidentialité des utilisateurs.
Tout l’écosystème digital s’étant développé autour des fameux cookies, lorsqu’un internaute refuse leur utilisation, les solutions de tracking traditionnelles dysfonctionnement. Cependant, il est possible de contourner ce problème grâce à des technologies de mesure permettant de distinguer le comportement des internautes qui autorisent les cookies de ceux qui les refusent.
C’est l’exemple de GA4 et Google Ads que nous allons explorer aujourd’hui.
En effet, le machine learning utilisé sur les données incomplètes capturées lorsque les utilisateurs refusent les cookies de Analytics va permettre de reconstituer les données manquantes grâce à des modèles comportementaux basés sur des utilisateurs similaires ayant accepté les cookies. Ainsi, il permet de modéliser les données manquantes pour qu’elles correspondent le plus fidèlement possible à la réalité tout en respectant les préférences des utilisateurs sur l’utilisation de cookies.
Qu’est-ce qui rend possible la modélisation des données manquantes ?
Le machine learning dans le cas de GA4 se base sur 2 constats :
- Nous avons un échantillon moindre mais suffisant d’utilisateurs qui acceptent les cookies. Même si nous avons une perte de mesures liée à ce canal, nous continuons à collecter des données utiles pour analyser le comportement type d’un utilisateur comme la fréquence, la récence, et le parcours.
- Nous pouvons toujours mesurer les événements puisqu’il ne s’agit pas de données personnelles. C’est à dire que nous pouvons toujours compter, par exemple, le nombre de ventes, le nombre d’ajouts au panier, de prospects, etc. ; le plus important est de s’assurer que chaque événement soit unique, d’où l’importance d’attribuer un ID unique à chaque événement afin d’éviter les biais liés aux doubles comptages.
Que fait le machine learning GA4 ?
En simplifiant à l’extrême, le machine learning effectue une succession de règles de 3 afin d’extrapoler les données manquantes en croisant les données de comptage et les données d’attribution et comportements basés sur des cookies dont nous avons le consentement. Bien sûr, le machine learning appliqué par Google sur GA4 et les données Google Ads est bien plus complexe pour s’assurer une véracité, et l’élimination de biais potentiels. Ainsi, GA4, et Google Ads sont en mesure, grâce au machine learning de recomposer les données manquantes dans la matrice.
C’est d’ailleurs pour cela que les données de GA4 sont si longues à remonter en version gratuite car il faut suffisamment de données pour l’algorithme pour recomposer les données. Ce délai est plus court sur la version payante de GA4 360 pour deux raisons. D’une part, pour des raisons commerciales. D’autre part, les volumes de données sont souvent plus importants pour les comptes disposant de cette licence ce qui se traduit par des données extrapolées qui remontent beaucoup plus rapidement.
Par contre, pour que cette modélisation fonctionne, il faut respecter 2 conditions :
- Mettre en place le consent mode Google
- Charger la balise GA4 dans tous les cas, et transmettre le consentement de l’utilisateur à GA4 afin que la balise adopte le bon comportement
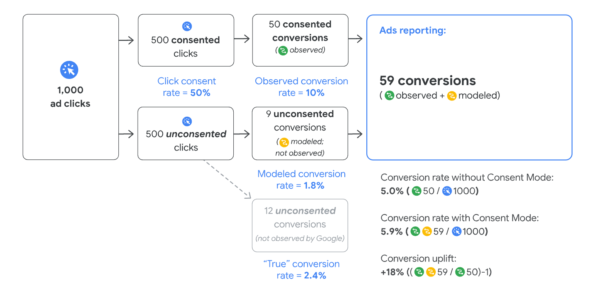
A l’avenir, les données web seront une combinaison de données mesurées et estimées, et grâce au machine learning nous pourrons estimer le plus justement possible les données pour être proche des 100% d’exactitude.
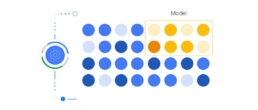
Le schéma suivant montre les données utilisateurs observées (en bleu). Nous pouvons voir qu’il en manque une partie (coin supérieur droit) représentant les données des utilisateurs refusant l’utilisation de cookies. Grâce au machine Learning, nous sommes en mesure de modéliser ces données manquantes (en jaune et orange).
Source: Google Marketing Platform, « Conversion modeling through Consent Mode in Google Ads » – 2021.
Toutefois, est-ce que ces calculs sont justes? Y-a-t-il des biais ?
Nous avons fait des tests sur plusieurs clients, et nous avons pu vérifier que le machine learning peut reconstituer la part des données à 10% près de la réalité. Nous conseillons donc de mettre en place un protocole interne pour valider la véracité des données de GA4, et contrôler régulièrement s’ il n’y a pas des écarts trop importants. Si vous êtes dans les 10-15%, vous êtes dans la moyenne du marché.
Conclusion :
Avec la mise en place de GA4, Google a prouvé que le machine learning est viable et fournit des données proches de la réalité tout en respectant la vie privée des utilisateurs, ce qui permet de continuer de mesurer les performances et d’optimiser efficacement les campagnes.
Les plateformes médias, tracking et d’analytics qui n’ont pas encore amorcé cette transition en 2023 risquent d’en subir les conséquences. En effet, plusieurs acteurs ont pris une avance considérable afin de ne pas trop subir les pertes de données utilisateurs. En tant que responsable marketing, il est important de questionner comment les outils que vous utilisez vont traiter la disparition d’un certain nombre de cookies, et la raréfaction de certains autres. Google et Meta sont en bonne voie pour prendre ce virage avec la combinaison d’un certain nombre de points de collecte combinés et du machine learning. Toutefois, êtes-vous prêt ainsi que vos solutions technologiques à prendre le virage 2023?